
Un modelo de IA que rompe esquemas
Índice de contenidos
¿Te imaginas que una inteligencia artificial pueda razonar de manera efectiva sin ser un modelo enorme? Aquí entra en juego DeepSeek-R1, un nuevo modelo creado por un reconocido laboratorio chino. La mayoría de las teorías actuales dicen que para lograr razonamiento en IA, se necesitan modelos gigantescos. Pero DeepSeek-R1 demuestra que eso no es del todo cierto. Utilizando métodos ingeniosos de entrenamiento, logra un rendimiento similar al de los modelos más avanzados, ¡pero usando mucho menos poder computacional! Asombroso, ¿no?
¿Qué hace único a DeepSeek-R1?
El desarrollo de modelos de inteligencia artificial ha avanzado muchísimo, pero enseñarles a razonar sigue siendo un desafío. Muchos modelos necesitan entrenarse con grandes cantidades de datos supervisados (es decir, con humanos corrigiendo las respuestas), lo que puede ser caro y lento. DeepSeek-R1 tomó un enfoque diferente: usar un tipo de entrenamiento llamado aprendizaje por refuerzo (reinforcement learning o RL), donde el modelo aprende de sus propios errores y aciertos. Este enfoque le permitió mejorar sus habilidades de razonamiento de manera eficiente.
Antes de este modelo, los investigadores ya habían probado una versión inicial llamada DeepSeek-R1-Zero, que fue capaz de razonar usando solo aprendizaje por refuerzo. Sin embargo, esa versión tenía problemas: a veces era difícil de entender, y mezclaba idiomas en las respuestas. Por eso, se creó DeepSeek-R1, que solucionó estos problemas y mejoró aún más las capacidades del modelo.
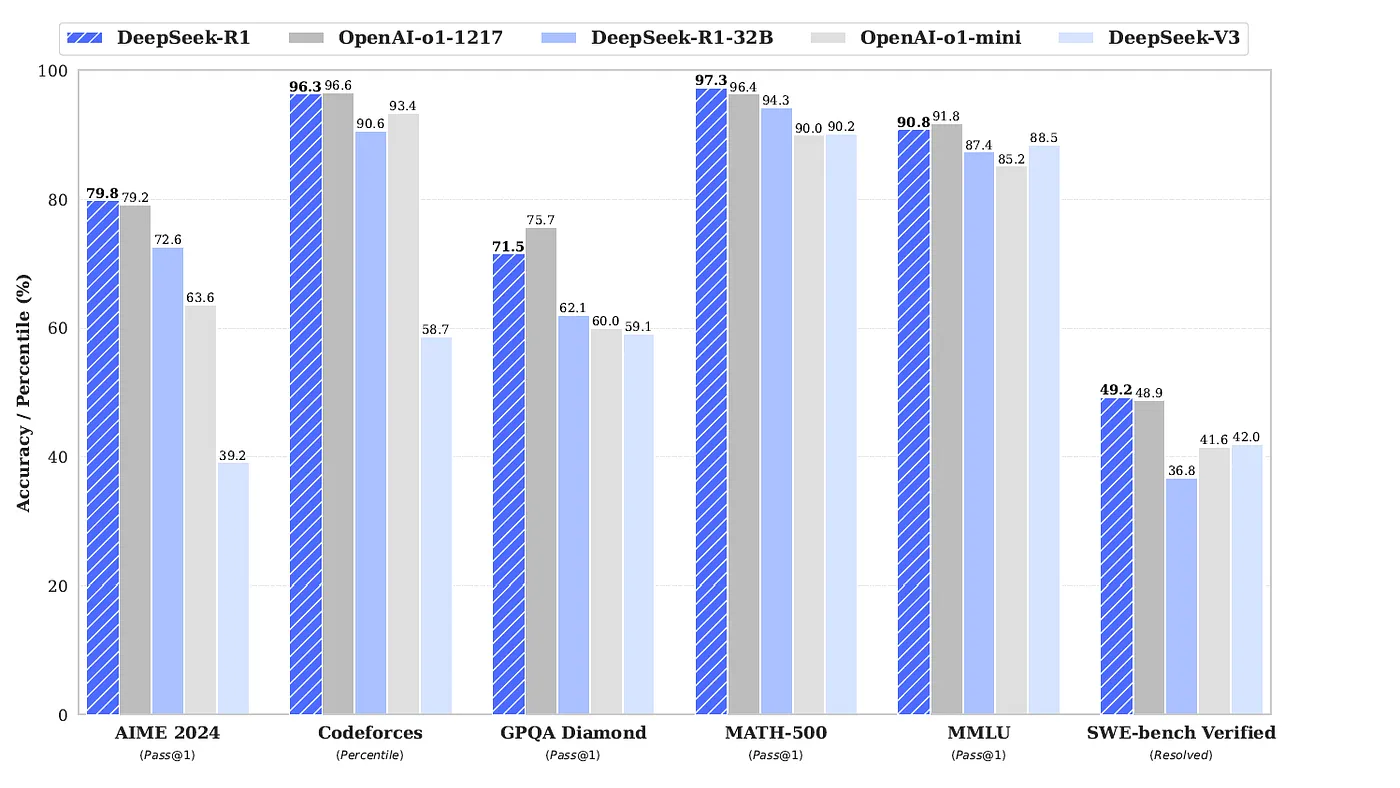
¿Cómo entrenaron a DeepSeek-R1?
El proceso de entrenamiento tuvo varias etapas, y aquí lo explicamos de manera sencilla:
- Un comienzo con ejemplos claros:
Antes de que el modelo aprendiera por su cuenta, se le dieron ejemplos de alta calidad para ayudarlo a entender cómo razonar mejor. Estos ejemplos incluían respuestas detalladas que mostraban los pasos para resolver problemas, como en matemáticas o lógica. - Aprender de sus propios errores:
Una vez que tuvo una base sólida, el modelo pasó a la etapa de aprendizaje por refuerzo. Aquí, evaluó sus propias respuestas, ajustó su forma de pensar y mejoró poco a poco. Esto le permitió desarrollar estrategias más avanzadas, como reflexionar sobre posibles errores y buscar mejores soluciones. - Hacerlo más fácil de entender:
Para asegurarse de que las respuestas fueran claras y útiles, se usó un formato estándar que incluía un resumen al final de cada respuesta, lo que hacía que fuera más fácil de leer para las personas.
¿Por qué esto es importante?
Lo más impresionante de DeepSeek-R1 es que muestra que una IA puede aprender a razonar sin necesidad de ser gigantesca o tener enormes cantidades de datos supervisados. Además, sus conocimientos se pueden transferir a otros modelos más pequeños, lo que hace que esta tecnología sea más accesible y eficiente.
Por ejemplo, modelos más pequeños como Qwen o Llama mejoraron significativamente en tareas como resolver problemas matemáticos, responder preguntas complejas y analizar documentos, todo gracias a lo que aprendieron de DeepSeek-R1.
¿Qué sigue para DeepSeek-R1?
Aunque DeepSeek-R1 ya es un gran avance, los investigadores tienen planes para mejorarlo aún más. Por ejemplo:
- Hacer que sea más útil en conversaciones largas o tareas de programación.
- Evitar que mezcle idiomas cuando responde.
- Hacerlo más robusto para responder preguntas en formatos complejos o inusuales.
Diferencias entre DeepSeek r1 y ChatGPT o1
| Características | DeepSeek-R1 | ChatGPT o1 |
|---|---|---|
| Tamaño del modelo | Más pequeño y eficiente, utiliza menos recursos computacionales. | Modelo grande que sigue la teoría de que el razonamiento requiere escalado. |
| Método de entrenamiento | Principalmente basado en aprendizaje por refuerzo (RL) y uso de datos iniciales mínimos. | Afinación supervisada intensiva (SFT) con grandes cantidades de datos. |
| Uso de aprendizaje por refuerzo | Sí, en múltiples etapas: primero datos iniciales y luego RL puro para mejorar razonamiento. | No depende exclusivamente de RL; combina RL con entrenamiento supervisado. |
| Capacidades de razonamiento | Logra un razonamiento avanzado con menos recursos mediante un postentrenamiento innovador. | Razonamiento fuerte, pero depende de modelos grandes y costosos. |
| Legibilidad de las respuestas | Mejorada con un formato que incluye un resumen y pasos de razonamiento claros. | Respuestas claras, pero no estructuradas de forma estándar. |
| Aplicaciones destacadas | Muy fuerte en tareas de matemáticas, lógica, ciencias y STEM en general. | Versátil, adecuado para una variedad más amplia de tareas generales. |
| Costo computacional | Menor costo computacional, ideal para usuarios con menos recursos. | Alto costo computacional debido al tamaño del modelo. |
| Innovaciones clave | – Uso de datos iniciales mínimos («cold-start»). – Distilación a modelos más pequeños. |
– Uso avanzado de entrenamiento supervisado. – Modelos de gran escala. |
| Transferencia a otros modelos | Capacidades de razonamiento transferidas a modelos más pequeños (ej. Qwen, Llama). | No se menciona distilación específica en ChatGPT o1. |
| Accesibilidad | Diseñado para ser más eficiente y accesible, ideal para investigaciones y recursos limitados. | Más limitado en accesibilidad debido al alto costo de entrenamiento. |
Conclusión:
- DeepSeek-R1 destaca por su eficiencia, innovación en el uso del aprendizaje por refuerzo y su capacidad para lograr razonamiento avanzado con menor costo computacional.
- ChatGPT o1 sigue un enfoque más tradicional, priorizando modelos grandes y datos supervisados, lo que lo hace más versátil pero menos eficiente en términos de recursos.
En resumen
DeepSeek-R1 es un modelo que está cambiando la manera en que entendemos el razonamiento en inteligencia artificial. Con métodos de aprendizaje innovadores y un enfoque práctico, este modelo no solo es eficiente, sino también un ejemplo de cómo la IA puede ser más accesible y útil para todos. Además, al compartir este modelo abiertamente, los investigadores están ayudando a que toda la comunidad científica avance en este campo.
¿No es emocionante? ¡Estamos viviendo una era en la que las máquinas no solo procesan información, sino que también empiezan a «pensar» de maneras más complejas!

Emma Llensa es consultora y formadora especializada en marketing digital e inteligencia artificial aplicada al crecimiento de negocios. Dirige la Academia Diffuze, donde ayuda a emprendedores y marcas a crear sistemas de ventas, contenido y automatización sostenibles. Está especializada en Meta Ads, embudos de conversión, IA para productividad y automatizaciones con Make, y es creadora de formaciones como ChatGPT Mastery, Meta Ads Élite y Automatizaciones con IA.