
Introducción
Índice de contenidos
En los últimos años, la inteligencia artificial (IA) ha demostrado avances impresionantes, llegando a desempeñar tareas creativas, analizar datos masivos y resolver problemas antes reservados a expertos humanos. Modelos de lenguaje como GPT-4 ya alcanzan puntajes casi perfectos en evaluaciones estándares, lo que plantea un nuevo desafío: ¿cómo medir el verdadero límite de sus capacidades de razonamiento avanzado?
Para la comunidad de negocios y marketing, comprender hasta dónde llega el “cerebro” de estas IA es crucial. Evaluar su habilidad para resolver problemas complejos no es solo un ejercicio académico, sino una necesidad práctica para saber en qué tareas podemos confiar a la IA y en cuáles aún es preciso el juicio humano.
Es en este contexto que nace Humanity’s Last Exam (en español, “El último examen de la humanidad”), una prueba concebida para poner a las inteligencias artificiales más avanzadas contra las cuerdas de la sabiduría experta. A continuación, exploraremos qué es exactamente este examen, quién está detrás de su creación, cuál es su propósito y metodología, y qué revelan los resultados obtenidos por diversos modelos de IA punteros.
Un examen definitivo: ¿qué es Humanity’s Last Exam y por qué se creó?
Humanity’s Last Exam (HLE) es un nuevo benchmark diseñado por Dan Hendrycks, investigador del Center for AI Safety (CAIS), en colaboración con la empresa Scale AI. Su propósito es evaluar si las IA han alcanzado un nivel de razonamiento y conocimiento comparable al de un experto humano de alto nivel.
El examen consta de 3.000 preguntas extremadamente desafiantes en más de 100 disciplinas, desde matemáticas avanzadas hasta humanidades y ciencias naturales. Su desarrollo contó con la participación de más de 1.000 expertos de diversas universidades y empresas tecnológicas, quienes aportaron preguntas diseñadas para ser prácticamente imposibles para los modelos actuales de IA.
La necesidad de crear este examen surgió porque los modelos de IA más avanzados comenzaron a saturar los benchmarks tradicionales, logrando puntajes cercanos al 90% en pruebas como MMLU y GSM8K. Sin embargo, estos exámenes no necesariamente reflejan una comprensión profunda o un razonamiento genuino, sino que pueden haber sido memorizados o aprendidos a través de estrategias de optimización.
Metodología del examen
Para garantizar que el examen fuera realmente difícil para las IA, el equipo de HLE recopiló inicialmente 70.000 preguntas candidatas. Luego, probaron estos problemas en los modelos de IA más avanzados y eliminaron aquellos que pudieron responder correctamente. Finalmente, quedaron 3.000 preguntas de máxima dificultad que componen el examen definitivo.
Otra particularidad de Humanity’s Last Exam es que no todas las preguntas son de texto. Muchas incluyen imágenes, gráficos y tablas que los modelos deben interpretar, lo que añade una capa adicional de complejidad.
Las preguntas están diseñadas para evitar que las IA simplemente «adivinen» la respuesta correcta o usen estrategias de aprendizaje superficial. En su lugar, el examen requiere un razonamiento paso a paso y un análisis profundo de cada problema planteado.
Resultados: ¿cómo les fue a las IA?
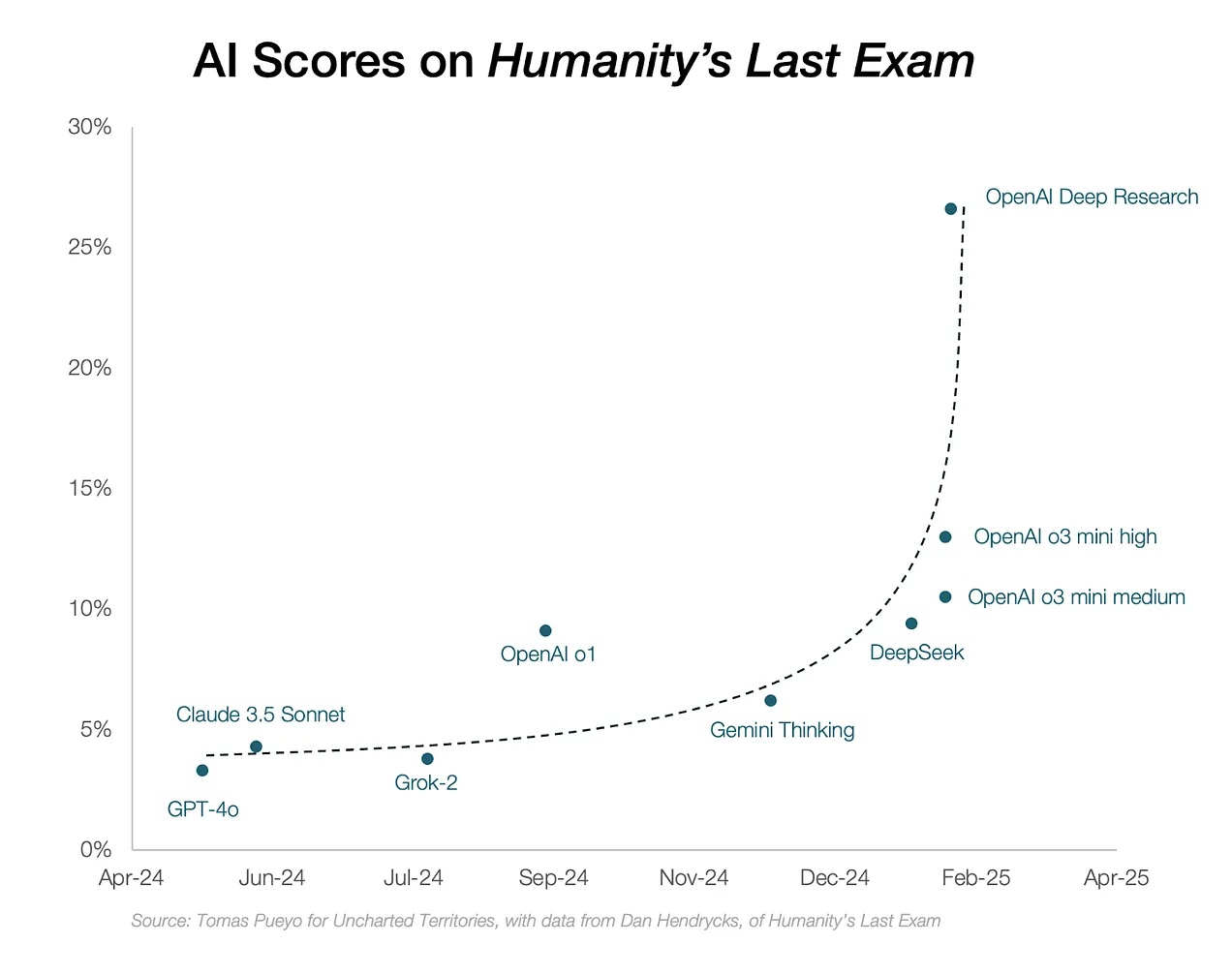
Los primeros modelos de IA probados en Humanity’s Last Exam obtuvieron resultados muy bajos. Algunos ejemplos destacados incluyen:
- GPT-4o (OpenAI) – 3% de respuestas correctas.
- Claude 3.5 Sonnet (Anthropic) – 4-5% de aciertos.
- Gemini 1.5 (Google) – 6-7% de respuestas correctas.
- DeepSeek R1 – 8-9% de aciertos.
- OpenAI Deep Research – 26% de aciertos, el mejor resultado hasta la fecha.
Estos resultados muestran que ninguna IA ha logrado superar ni el 10% de respuestas correctas en su configuración estándar, lo que indica que aún hay una gran brecha entre la inteligencia artificial y el conocimiento humano experto.
Sin embargo, OpenAI probó un nuevo sistema llamado Deep Research, que combina la potencia de GPT-4 con herramientas de búsqueda en internet, cálculo avanzado y razonamiento extendido. Este sistema logró resolver el 26% de las preguntas, lo que indica que el problema no es solo la capacidad de los modelos, sino también su acceso a información y la forma en que razonan.
Impacto de estos avances en los negocios, el marketing y la toma de decisiones
Los sorprendentes resultados de Humanity’s Last Exam tienen repercusiones importantes para empresas y profesionales del marketing que siguen de cerca la evolución de la IA. Por un lado, el hecho de que ninguna inteligencia artificial haya podido aprobar ni el 10% de este “examen final” pone en perspectiva las limitaciones actuales de la tecnología.
En situaciones que requieren razonamiento sofisticado, pensamiento crítico multidisciplinario o conocimientos verdaderamente especializados, las IA siguen necesitando asistencia humana o más desarrollo. Para las empresas, esto significa que —al menos por ahora— no es prudente delegar decisiones estratégicas completamente en una IA sin supervisión.
Un director de marketing no querría, por ejemplo, que un modelo genere un plan de negocio complejo si sabemos que frente a preguntas retadoras ese modelo falla el 95% de las veces y ni siquiera es consciente de sus propios errores. La confiabilidad sigue siendo un tema central: antes de poner una IA al volante de decisiones críticas, debemos asegurarnos de que realmente entienda el problema y sepa cuándo duda.
Por otro lado, los rápidos progresos observados auguran grandes oportunidades. Que en tan poco tiempo un agente como Deep Research lograra resolver más de una cuarta parte del HLE sugiere que, en un futuro cercano, las IA podrían manejar problemas complejos mucho mejor.
Los creadores de HLE incluso proyectan que para finales de 2025 algún modelo podría superar el 50% de aciertos en este examen.
¿Qué significaría tener una IA capaz de responder correctamente la mayoría de preguntas de nivel experto en decenas de disciplinas?
En el ámbito de negocios y marketing, esto podría equivaler a contar con un consultor o analista virtual de élite, disponible 24/7.
- Imaginemos estrategias de marketing desarrolladas tras analizar, en minutos, tendencias culturales, datos económicos, patrones de consumo y teoría de juegos, todo integrado por una IA con razonamiento casi humano.
- O tomar decisiones empresariales complejas (lanzamiento de un producto, inversión en cierto mercado, reestructuración organizativa) apoyándose en simulaciones y análisis generados por un modelo que ha demostrado poder resolver problemas dignos de un MBA y un PhD juntos.
Además, la existencia misma de Humanity’s Last Exam está impulsando una carrera entre las grandes tecnológicas por demostrar el poder de sus IA. Empresas como OpenAI, Google, Anthropic e incluso iniciativas de Elon Musk han aceptado el reto y compiten por escalar posiciones en este difícil “ranking” de inteligencia.
Este espíritu competitivo probablemente acelerará la innovación: cada punto porcentual ganado en HLE puede traducirse en mejoras que luego se apliquen en productos comerciales de IA.
Por ejemplo, una técnica que permita a un modelo entender mejor un diagrama científico (algo necesario para contestar ciertas preguntas del examen) luego podría incorporarse en herramientas de análisis de datos empresariales o en asistentes virtuales más inteligentes para presentaciones corporativas.
Para el mundo del marketing, que suele aprovechar cada avance en IA (desde segmentación automatizada hasta generación de contenido), las mejoras en capacidades de razonamiento significarán campañas más inteligentes y personalizadas.
Una IA más competente podría:
✅ Identificar nichos de mercado combinando información de distintas fuentes.
✅ Predecir comportamientos del consumidor con modelos causales más sólidos.
✅ Anticipar riesgos y oportunidades haciendo análisis que hoy requieren equipos enteros de consultores.
Sin embargo, es importante mantener una visión equilibrada. Hasta que las IA alcancen un rendimiento mucho más alto en evaluaciones como HLE, las decisiones empresariales de alto impacto deben tomarse con intervención humana y considerando las salvedades del caso.
Los resultados actuales nos recuerdan que la IA puede fallar estrepitosamente en escenarios nuevos, y en marketing un error de interpretación podría significar una campaña mal dirigida, o en negocios, una estrategia basada en supuestos erróneos.
La clave estará en usar la IA como un apoyo potente pero no infalible: una herramienta que ofrezca sugerencias y análisis avanzados, mientras que los expertos humanos validan y ajustan esas recomendaciones con su criterio y experiencia.
El futuro de la IA en la resolución de problemas complejos
Humanity’s Last Exam nos ofrece una mirada fascinante al estado actual y al potencial futuro de la inteligencia artificial. Hoy por hoy, ha dejado en evidencia que aún existe una brecha significativa entre lo que las mejores IA pueden hacer y el conocimiento experto humano en tareas inéditas.
Ningún modelo ha aprobado realmente este “último examen” – la mayoría ni se acercan – lo cual, lejos de ser una decepción, es útil para definir claramente el próximo gran objetivo en el desarrollo de IA.
Saber dónde están fallando las IA (y con qué grado de confianza equivocada) ayuda a investigadores y empresas a enfocar sus esfuerzos en esas áreas críticas.
Como señaló un miembro del equipo de HLE, esta prueba identifica las lagunas en el razonamiento de las IA y proporciona una hoja de ruta para la investigación y desarrollo futuros.
De hecho, cada pregunta que hoy ninguna máquina puede responder es un reto abierto para la comunidad: quizás mañana surja un nuevo algoritmo o arquitectura que logre resolverla.
A la vez, los rápidos progresos logrados en corto tiempo invitan al optimismo cauteloso.
El salto de menos del 10% a un 26% de aciertos gracias a un agente mejorado sugiere que no estamos ante límites insuperables, sino ante obstáculos que pueden vencerse con innovación y más potencia.
Si la predicción de superar el 50% de aciertos para fin de año se cumple, significará que las IA habrán aprendido a responder correctamente la mayoría de preguntas extremadamente complejas que les planteemos.
En ese punto, la discusión pasará de “¿pueden hacerlo?” a “¿qué implicaciones tiene que lo hagan?”.
Para el mundo empresarial y del marketing, esto podría marcar un antes y un después:
✔ Tener IA capaz de resolver problemas de nivel doctoral podría revolucionar la forma en que investigamos, planificamos estrategias y tomamos decisiones de alto nivel.
✔ Si las IA logran entender la causa y efecto de fenómenos del mundo real, su aplicación en negocios y marketing será aún más profunda.
✔ En lugar de generar informes o resúmenes, podrían predecir tendencias, optimizar inversiones y sugerir estrategias personalizadas.
Por supuesto, alcanzar y superar ese 50% (o incluso un 100% en el futuro) en Humanity’s Last Exam no significará que la IA lo sepa todo o que reemplace la intuición y creatividad humanas.
Pero sí será un indicador poderoso de que ha alcanzado un nuevo escalón en su evolución intelectual.
Algunos expertos ven al HLE como un hito necesario antes de confiar a la IA roles avanzados en investigación científica, ingeniería o gestión de sistemas críticos.
En otras palabras, si queremos IA verdaderamente autónomas en tareas complejas, primero deben demostrar su valía en exámenes como este.
Conclusión
En conclusión, Humanity’s Last Exam representa tanto un recordatorio de la humildad que aún debe tener la inteligencia artificial frente al vasto conocimiento humano, como un catalizador de innovación que está empujando los límites de lo que estas tecnologías pueden lograr.
Para los profesionales de marketing y negocios, seguir de cerca este tipo de evaluaciones es más que una curiosidad: es anticipar las capacidades que las próximas generaciones de IA traerán a nuestras herramientas y procesos.
El “último examen de la humanidad” no es el final de nada, sino el comienzo de una nueva etapa en la que las máquinas se esfuerzan por alcanzar la sabiduría humana.
Y cuando finalmente la alcancen (ya sea en meses o unos pocos años), estaremos preparados para integrar ese poder intelectual en nuestras empresas de forma responsable y estratégica, abriendo las puertas a innovaciones que hoy apenas podemos imaginar.
Referencias
- Hendrycks, D. et al. (2025). Humanity’s Last Exam: arXiv preprint.
- Scale AI. Scale AI and CAIS Unveil Results of Humanity’s Last Exam (2025).
- The Decoder. Frontier models fail hard at ‘Humanity’s Last Exam’ (2025).
- VnExpress International. Meet the Vietnamese engineer shaping AI’s toughest test (2025).
- Hindustan Times. OpenAI’s deep research can complete 26% of ‘Humanity’s Last Exam’ (2025).

Emma Llensa es consultora y formadora especializada en marketing digital e inteligencia artificial aplicada al crecimiento de negocios. Dirige la Academia Diffuze, donde ayuda a emprendedores y marcas a crear sistemas de ventas, contenido y automatización sostenibles. Está especializada en Meta Ads, embudos de conversión, IA para productividad y automatizaciones con Make, y es creadora de formaciones como ChatGPT Mastery, Meta Ads Élite y Automatizaciones con IA.